
Building AI powered apps with Laravel & Replicate

Over the past years I’ve built a handful of apps that heavily relied on LLM’s, diffusers and other AI models using Laravel. In this video, I’ll be showing you exactly how you can build your own AI-powered apps using Laravel and Replicate - so let’s dive in.
What is Replicate?
Running AI models locally, or maintaining and scaling your own machine learning infrastructure can be a massive pain.
Replicate allows you to run AI models in the cloud with a simple to use API. Think of it like a serverless function that you can invoke from your PHP code. You get charged for your usage per second, based on which GPU the model runs on.
Replicate has a library of thousands of community AI models you can run using an API, and you can also deploy and run your own models on their infrastructure.
And you get all of that without having to worry about infrastructure.
Replicate API
The way Replicate works is pretty easy, you first pick a model, for example Stable Diffusion: https://replicate.com/stability-ai/stable-diffusion
You can see every parameter we can send to the model using the API in the interface, and you can even try it out right within your browser.
These models are versioned, so we need to head over to the versions tab and click on the specific version we want to use, for example the (current) latest one:
We can then interact with this model using an API, so let’s head over to the HTTP tab where we can find a cURL request:
curl -s -X POST \
-H "Authorization: Bearer $REPLICATE_API_TOKEN" \
-H "Content-Type: application/json" \
-d $'{
"version": "ac732df83cea7fff18b8472768c88ad041fa750ff7682a21affe81863cbe77e4",
"input": {
"width": 768,
"height": 768,
"prompt": "an astronaut riding a horse on mars, hd, dramatic lighting",
"scheduler": "K_EULER",
"num_outputs": 1,
"guidance_scale": 7.5,
"num_inference_steps": 50
}
}' \
https://api.replicate.com/v1/predictionsDon't forget to setup your API key by setting the REPLICATE_API_TOKEN environment variable.
This API call creates something that’s called a ‘prediction’. Think of it as a job in Laravel that gets put on a queue. Whenever a worker is available, it’ll get picked up and the prediction will get updated as the model returns output.
To look at our prediction, we can navigate to replicate.com/p/{id} and we’ll see the output in the interface.
We can also check the status of the prediction by executing a GET request to the API as follows:
curl -s \
-H "Authorization: Bearer $REPLICATE_API_TOKEN" \
https://api.replicate.com/v1/predictions/...Client libraries
Replicate provides a couple of first party client libraries - for example in NodeJS. These libraries allow you to ‘run’ a model and wait for its output using promises. Essentially, this creates a prediction and polls the API every 500 miliseconds - and when the status is succeeded, failed or canceled the promise will be resolved.
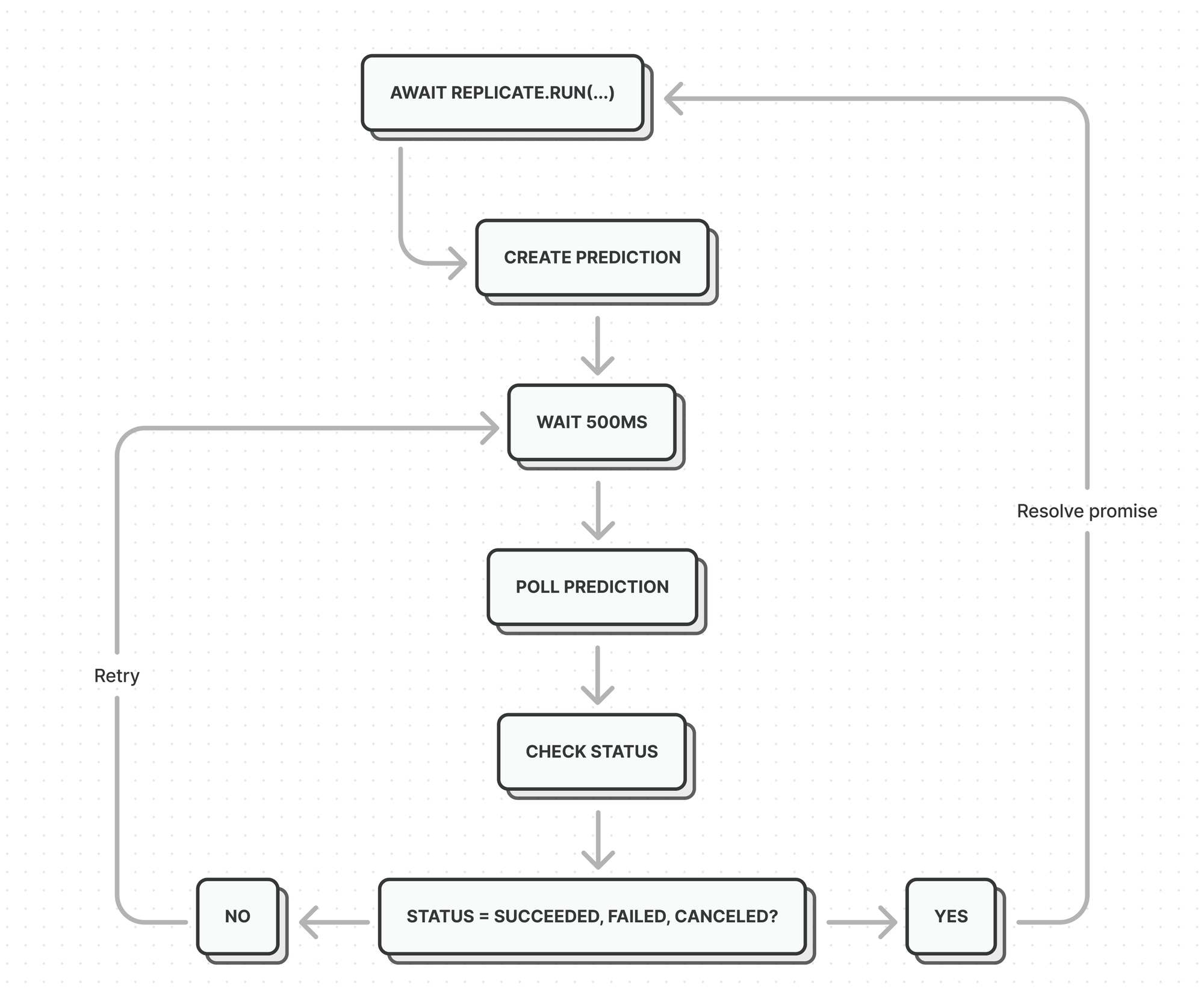
There were a couple of PHP clients available on Github, but they were all missing this - in my opinion - crucial feature, so I created my own PHP Replicate client with this ‘run’ functionality and open-sourced it for you to use.
 SabatinoMasala
SabatinoMasalaIntegration in Laravel
Now that we know how Replicate works, let’s integrate it in a Laravel project. Let’s create a new laravel project:
laravel new replicate-exampleAnd let’s include the Replicate client:
composer require sabatinomasala/replicate-phpNext up, let’s find our Replicate API token and put it in our .env file
Then, we can initialize the Replicate Client:
$token = env('REPLICATE_TOKEN');
$replicate = new SabatinoMasala\Replicate\Replicate($token);Now let’s find a model to run in the library https://replicate.com/explore - for example sdxl
Copy the version, head back over to the code, and let’s run this model:
$output = $replicate->run('stability-ai/sdxl:7762fd07cf82c948538e41f63f77d685e02b063e37e496e96eefd46c929f9bdc', [
'prompt' => 'A cat developing an app',
]);
// Display the image quick & dirty
header('Content-Type: image/png');
die(file_get_contents($output[0]));And then we can pass in our input parameters. You can find every parameter the model accepts in the Replicate web interface, and for now let’s just use the ‘prompt’ parameter.
When we visit our Laravel app, we’ll be presented with a nice image of a cat developing an app, and every time we refresh, the image updates - how cool is that?
Now - as you probably noticed, the request takes a pretty long time, so my advice to you is to never wait for a prediction to complete within a route handler. Instead, I always try to run models in queue workers, where the long duration has a lesser impact on the user experience.
Alternatively, you could also use webhooks and instead of running a model, you can create a prediction as follows:
$output = $replicate->predictions()->create('stability-ai/sdxl:7762fd07cf82c948538e41f63f77d685e02b063e37e496e96eefd46c929f9bdc', [
'input' => [
'prompt' => 'A cat developing an app',
],
'webhook' => 'https://webhook.site/21713260-31fe-4d70-ab1d-cc5a3965f504'
]);
dd($output->json());For trying out webhooks, I usually use webhook.site, so you can see every request come in. Now when you visit the Laravel app, you’ll see the request is very fast, and after a few seconds we’ll get a webhook notification that informs us the prediction has completed.
I usually use webhooks when I have a more elaborate setup using websockets, for example with Laravel Reverb. While the prediction is running, we can show a spinner in our frontend, and when the webhook gets called, we can broadcast an event to inform the frontend the prediction completed.
Let’s look at another example, this time, we’ll chain 2 models together: a large language model, and a diffuser.
$output = $replicate->run('meta/meta-llama-3-70b-instruct', [
'prompt' => 'You are a creative director for an animated movie, your task is to describe a scene in intricate detail in 200 characters or less. Only reply with the description, nothing else. Describe a random scene in a fantasy movie',
], function($prediction) {
\Log::info($prediction->json('output'));
});
// $output is an array of 'tokens', so we need to implode the array into a sentence
$string = implode('', $output);
$output = $replicate->run('stability-ai/sdxl:7762fd07cf82c948538e41f63f77d685e02b063e37e496e96eefd46c929f9bdc', [
'prompt' => $string,
]);
header('Content-Type: image/png');
die(file_get_contents($output[0]));We’ll use LLama 3 as our Large Language Model, and because this is an official model, we are not required to pass in a version.
When running the model, we can also get updates by passing in a function as a third parameter. In our case, we can now follow along in the logs, and you’ll see the tokens come in while the request is ongoing.
Again - in a more elaborate setup, you could stream this to the frontend using websockets, so the user will get feedback much quicker.
Next up, we can send the output of the LLM into our diffuser as before, and behold, now every time we refresh, we’ll get a new random fantasy scene - pretty cool.

Tips & tricks
Here are a couple of things I learned while working with AI models on Replicate over the past years:
- Never assume a model will run instantly
Because of the way Replicate works, you may have to deal with cold boots that can take anywhere from 2 to 5 minutes. This is especially the case when you’re working with less popular models. When a cold boot happens, the status of the prediction will be queued, and once the model is booted, it will start running. - Use webhooks for very long tasks
Replicate allows you to finetune certain models, and this process can take up to 30 minutes. In my experience, these finetuning tasks work best when combined with webhooks. - Integrate websockets
As we saw in the examples, it can sometimes take a couple of seconds for the model to complete running. That’s why it’s very important to give your user feedback as soon as possible. You can use Laravel Reverb if you’re on Laravel 11, or you can use something like Soketi if you’re on an older version of Laravel. Both of these support the Pusher protocol, so they’re pretty much interchangeable.
And that concludes the article, I hope you learned a thing or two, and I will see you in the next one!
No spam, no sharing to third party. Only you and me.